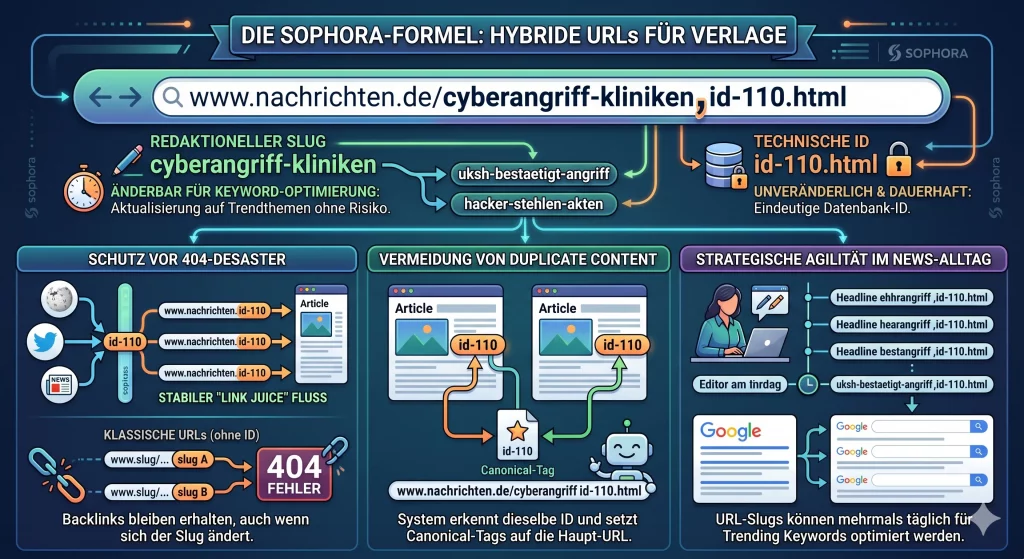
Wenn Sie die digitalen Nachrichten der Tagesschau, des NDR oder SWR lesen, navigieren Sie unbewusst durch eine der cleversten technischen Architekturen im deutschen Internet. Ein genauer Blick auf die Adresszeile des Browsers offenbart ein wiederkehrendes Muster: Ein langer, lesbarer Text (der Slug), gefolgt von einem Komma und einer kryptischen Zahl (der Datenbank-ID). Was auf den ersten Blick wie ein unschöner Kompromiss in der Programmierung wirkt, ist bei forensischer SEO-Betrachtung ein hochpräzises Instrument zur Sicherung digitaler Autorität.
Ich habe die Suchmaschinen-Mechanik dieser hybriden URL-Strukturen, wie sie das Content-Management-System Sophora verwendet, tiefgehend analysiert. Es geht hier nicht um bloße Ästhetik. Es geht um den Schutz von Backlinks, die Vermeidung von toxischem „Duplicate Content“ und die strategische Agilität im redaktionellen Alltag. Hier ist die schonungslose Aufarbeitung, warum die Trennung von Lesbarkeit und Datenbank-Identifikation für Google einen enormen Mehrwert bringt und wie diese Technik Verlage vor dem gefürchteten Ranking-Absturz bewahrt.
Der Schutz vor dem 404-Desaster
In der rasanten Welt des News-Journalismus ändern sich Überschriften im Minutentakt. Eine Eilmeldung startet als „Cyberangriff auf Kliniken vermutet“, wird eine Stunde später zu „BSI bestätigt Cyberangriff auf UKSH“ und abends zu „Hacker stehlen 2.500 Patientenakten“.
Bei einem klassischen System (wie einer Standard-WordPress-Installation) basiert die URL rein auf diesem Text. Ändert die Redaktion die Überschrift und passt den URL-Slug an, entsteht eine völlig neue Adresse. Die alte URL führt plötzlich ins Leere – auf eine 404-Fehlerseite. Das ist ein SEO-Albtraum. Nachrichtenartikel sammeln in den ersten Stunden ihrer Publikation hunderte wertvolle Backlinks von Wikipedia, Twitter, anderen Zeitungen und Foren. Führt die alte URL plötzlich ins Leere, verpufft all dieser hart erarbeitete „Link Juice“ (die Weitergabe von PageRank) komplett.
Die hybride Architektur (z.B. cyberangriff-kliniken,id-110.html) löst diesen Knoten brillant. Die Server der Sender sind so programmiert, dass sie für die Auslieferung des Artikels ausschließlich den Teil nach dem Komma (id-110) auswerten. Die Redaktion kann den Text vor dem Komma zehnmal am Tag anpassen, um ihn auf die aktuellsten Google-Suchanfragen (Trending Keywords) zu optimieren. Jeder externe Link, der in der Vergangenheit gesetzt wurde, funktioniert weiterhin fehlerfrei, da das System das Dokument anhand der unantastbaren ID findet. Der Flow des organischen Traffics bleibt kompromisslos stabil.
Keyword-Agilität vs. Duplicate Content
Die Flexibilität, den SEO-Slug (den lesbaren Text) ständig anzupassen, ist ein massiver strategischer Vorteil. Redakteure können auf neue Suchmuster reagieren, ohne die IT-Abteilung für komplexe 301-Weiterleitungen (Redirects) einschalten zu müssen.
Doch diese Freiheit birgt eine technische Gefahr, die von der Suchmaschine rigoros abgestraft wird: Duplicate Content (doppelte Inhalte). Wenn ein Artikel unter drei verschiedenen URLs (titel-1,id-110.html, titel-2,id-110.html etc.) aufrufbar ist, weiß der Googlebot nicht, welche Version er im Index behalten soll. Die URLs kannibalisieren sich gegenseitig in der Sichtbarkeit.
Professionelle CMS-Architekturen wie Sophora kontern dieses Risiko durch eine doppelte technische Absicherung:
- Der Canonical-Tag: Egal mit welchem veralteten Text-Slug der Artikel aufgerufen wird, im Quelltext der Seite ist immer ein
<link rel="canonical">definiert, der exakt auf die aktuellste, von der Redaktion gewollte URL-Version verweist. So weiß der Google-Crawler immer, welches die „Haupt-URL“ ist. - Auto-Redirects: Sehr gut konfigurierte Systeme werten den Aufruf aus. Erkennt der Server, dass jemand eine alte URL (z.B. aus einem gestrigen Tweet) aufruft, lädt er nicht einfach den Artikel, sondern sendet einen sofortigen 301-Redirect auf die neue, aktuelle Überschriften-URL.
Die Semantik für den Crawler
Warum verzichtet man dann nicht einfach komplett auf den Text und nutzt nur noch IDs wie artikel.html?id=110?
Die Antwort liegt in der Semantik. Auch wenn Google heute extrem fortschrittlich ist, liest der Algorithmus die URL weiterhin, um den initialen Kontext einer Seite zu verstehen (Search Intent). Schlüsselwörter in der URL sind ein direkter Relevanzfaktor. Zudem werden URLs oft „nackt“ (ohne Linktext) in Foren oder Messengern geteilt. Ein Nutzer klickt weitaus häufiger auf einen Link, in dem er Worte wie cyberangriff und patientendaten lesen kann, als auf eine kryptische Ziffernfolge. Diese erhöhte Klickrate (CTR) ist ein starkes, positives Nutzersignal für Google.
In letzter Konsequenz stellt die hybride URL-Struktur aus lesbarem Slug und fester Datenbank-ID die absolute Speerspitze der technischen Suchmaschinenoptimierung für große Publisher dar. Sie vereint das Beste aus zwei Welten: Maximale Agilität für Redakteure, um auf Echtzeit-Trends zu optimieren, und eiserne Stabilität für die Server-Architektur, um nicht einen einzigen wertvollen Backlink durch 404-Fehler zu verbrennen. Wer Content in industriellem Maßstab publiziert und dieses Prinzip ignoriert, verliert den Kampf um die vordersten Plätze bei Google News noch vor dem ersten Klick.
Andere Artikel: