- Einführung in das neue Suchmaschinen-Paradigma
- Chronologie der kaskadierenden Algorithmus-Updates (2024–2026)
- Anatomie des März-Spam-Updates (March 2026 Spam Update)
- Analyse der SERP-Volatilität: Registrierung des „Googlequake“
- Ranking-Architektur im März 2026: Die drei Säulen der neuen SEO
- Singularität im E-Commerce: Universal Commerce Protocol (UCP)
- Sektorale Analyse: Gewinner und Verlierer
- Reaktion der Fachwelt: Die Anpassungskrise
- Strategisches Anpassungs- und Wiederherstellungsprotokoll (Recovery Guide)
- Zusammenfassung
Einführung in das neue Suchmaschinen-Paradigma
Das Frühjahr 2026 markierte einen Wendepunkt in der Evolution des Such-Ökosystems und leitete eine beispiellose strukturelle Transformation der Ranking-Architektur von Google ein. Am 27. März 2026 um 02:14 Uhr pazifischer Zeit (PDT) begann der weltweite Rollout des Core-Algorithmus-Updates – das Google March 2026 Core Update. Dieses Ereignis ist keine isolierte Anpassung der Suchergebnisse; es stellt den Höhepunkt einer Reihe von algorithmischen Verschiebungen dar, die in der Fachwelt des digitalen Marketings als „The Great Reset“ (Der große Neustart) bezeichnet werden.
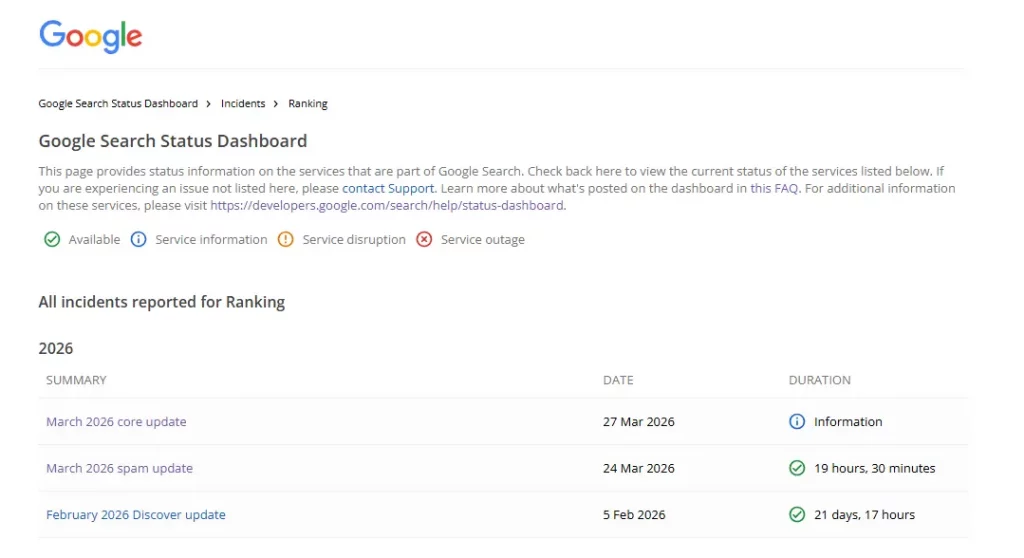
Die Einzigartigkeit des aktuellen Analysezeitraums liegt im Phänomen der sogenannten „Kombi-Updates“ (combo updates). Die Veröffentlichung des März-Core-Updates erfolgte nur wenige Tage nach dem Release des allerersten exklusiven Updates für den mobilen Empfehlungs-Feed (February 2026 Discover Core Update) und nur drei Tage nach Abschluss des schnellsten Spam-Updates der Geschichte (March 2026 Spam Update). Eine derartige Überlagerung mehrerer unabhängiger Systeme zur Qualitätsbewertung, Spam-Filterung und Implementierung neuer kommerzieller Protokolle schuf ein Diagnoseumfeld von außergewöhnlicher Komplexität.
Die Untersuchung der bereitgestellten Datensätze zeigt, dass sich die Alphabet Inc. vollständig von der isolierten Bewertung von Webseiten verabschiedet, die auf traditionellen Metriken wie Textrelevanz und Backlink-Profil basierte. Der strategische Vektor hat sich in Richtung vergleichendes Ranking, mathematische Bewertung der semantischen Einzigartigkeit (Information Gain), ultimative Anforderungen an die Verifizierung der Autorität (E-E-A-T), strenge Schwellenwerte für die Nutzererfahrung (einschließlich des neuen INP-Standards von 150 Millisekunden) und die Integration von KI-Agenten über das Universal Commerce Protocol (UCP) verlagert. Dieser Bericht liefert eine umfassende Analyse der technischen, semantischen und kommerziellen Auswirkungen des Rollouts des März-Updates 2026, gestützt auf empirische Daten, SERP-Volatilitätskennzahlen und den Expertenkonsens.
Chronologie der kaskadierenden Algorithmus-Updates (2024–2026)
Für ein tiefes Verständnis der Mechanik des März-Updates 2026 ist es unerlässlich, die Kette der algorithmischen Ereignisse im Vorfeld des Starts zu analysieren. Suchmaschinen werden nicht mit jedem neuen Update auf den Nullzustand zurückgesetzt; sie akkumulieren historische Daten und erhöhen schrittweise die Komplexität von Filtermechanismen und Machine-Learning-Modellen. Die Analyse der langfristigen Chronologie zeigt einen evolutionären Übergang von langwierigen Rollout-Zyklen hin zu rasanten, vorberechneten algorithmischen Anpassungen, die von neuronalen Netzen gesteuert werden.
Nachfolgend finden Sie eine detaillierte Chronologie der kritischen Updates, die die Sucharchitektur bis März 2026 geprägt haben.
| Name des Updates | Startdatum | Dauer des Rollouts | Hauptmerkmal und algorithmisches Ziel |
| August 2024 Core Update | 15. August 2024 | 19 Tage, 4 Stunden | Integration von AI Overviews in das System zur Bewertung der Auswirkungen von Core Updates. |
| March 2025 Core Update | 13. März 2025 | 13 Tage, 21 Stunden | Reguläre Systemanpassung mit dem Ziel, Clickbait zu reduzieren und hilfreiche Inhalte zu fördern. |
| June 2025 Core Update | 30. Juni 2025 | 16 Tage, 18 Stunden | Großflächiges Update; teilweise Wiederherstellung von Websites, die vom HCU (Helpful Content Update) 2023 betroffen waren. |
| August 2025 Spam Update | 26. August 2025 | 26 Tage, 15 Stunden | Langwierige Bereinigung des Suchindex von manipulativen Link-Praktiken. |
| December 2025 Core Update | 11. Dezember 2025 | 18 Tage, 2 Stunden | Grundlegende Neukalibrierung der Suchintention; endgültiger Übergang zum vergleichenden Seiten-Ranking. Massenhafte Abwertung von Nachrichtenaggregatoren und Verzeichnissen (Wikipedia verlor über 435 Sichtbarkeitspunkte) zugunsten von Marken-E-Commerce. |
| February 2026 Discover Update | 5. Februar 2026 | 21 Tage, 17 Stunden | Das erste exklusive Update für den Discover-Feed in der Geschichte. Fokus auf das Filtern von Clickbait und die Förderung tiefgehender lokaler Berichterstattung. Rückgang der Anzahl einzigartiger Domains im US-Feed. |
| March 2026 Spam Update | 24. März 2026 | 19 Stunden, 30 Minuten | Die schnellste Implementierung in der Geschichte des Google Status Dashboards; automatisierte Spam-Beseitigung auf Basis des SpamBrain-Systems. |
| March 2026 Core Update | 27. März 2026 | Bis zu 14 Tage (laufend) | Großflächige Bewertung der Inhaltsqualität, Integration neuer INP-Schwellenwerte, Bewertung des Information Gains und Filterung KI-generierter Inhalte ohne E-E-A-T. |
Signale aus dem vorherigen Update: Lektionen aus dem Dezember 2025
Das Dezember-Update 2025 legte das technische und ideologische Fundament für die Ereignisse im März 2026. Es festigte endgültig das Muster, bei dem Ranking-Systeme ausschließlich vergleichend (comparative) und nicht mehr regelbasiert (rule-based) agieren. Früher konnten Webseiten relativ isoliert bewertet werden und sammelten Punkte für das Erfüllen einer SEO-Checkliste. Nach Dezember 2025 wird der Wert einer Seite streng im Vergleich zu Mitbewerbern für eine bestimmte Suchanfrage gemessen. Dieser Paradigmenwechsel erklärt das massenhafte Phänomen des Traffic-Verlusts bei stabilen Ressourcen: Das Ranking sinkt nicht, weil sich auf der Website negative Änderungen ergeben haben, sondern weil der Inhalt des Konkurrenten algorithmisch als umfassender und wertvoller eingestuft wird.
Die Innovation vom Februar 2026: Das isolierte Discover-Update
Das Februar-Update (February 2026 Discover Core Update) verdient besondere analytische Aufmerksamkeit, da es einen Präzedenzfall für gezielte algorithmische Eingriffe in das mobile Ökosystem schuf. Traditionell betrafen Core-Updates alle Suchoberflächen gleichzeitig. Der Februar-Rollout, der vom 5. bis 27. Februar andauerte, konzentrierte sich ausschließlich auf den Empfehlungs-Feed Discover. Offizielle Erklärungen des Unternehmens hoben drei Ziele hervor: die Förderung lokal relevanter Inhalte, die Vernichtung von Clickbait und die Priorisierung origineller, tiefgehender Analysen gegenüber umgeschriebenen Texten. Die Ergebnisse waren messbar und radikal: Die Anzahl der einzigartigen Domains, die im amerikanischen Discover-Feed auftauchen, sank von 172 auf 158. Dies zeigt, dass der Algorithmus den Pool vertrauenswürdiger Quellen (Trust Pool) verengt hat und Websites aussortiert, deren Geschäftsmodell auf der Aggregation von Trendthemen ohne Mehrwert basierte.
Anatomie des März-Spam-Updates (March 2026 Spam Update)
Eine adäquate Interpretation des März-Core-Updates ist ohne die Dekonstruktion des Spam-Updates (March 2026 Spam Update), das ihm nur 72 Stunden vorausging, unmöglich.
Das Ereignis begann am 24. März 2026 um 12:18 Uhr PDT (der offizielle Beginn des Vorfalls wurde um 12:00 Uhr PDT aufgezeichnet) und wurde am 25. März um 07:39 Uhr PDT vollständig abgeschlossen. Mit einem globalen Rollout in allen Sprachzonen von weniger als 20 Stunden (19 Stunden und 30 Minuten) brach dieses Update alle historischen Geschwindigkeitsrekorde im Google Search Status Dashboard. Zum Vergleich: Ein ähnliches Spam-Update im August 2025 dauerte fast 27 Tage, das vom Dezember 2024 sieben Tage und das vom März 2024 14 Tage.
Präkompilierungsmechanik und die Evolution von SpamBrain
Die extreme Implementierungsgeschwindigkeit (weniger als ein Tag für Milliarden von Webseiten) schließt die Möglichkeit von Echtzeitberechnungen während des Rollouts selbst aus. Technische Analysen deuten darauf hin, dass dieses Update vollständig vorberechnet (pre-computed) und in die Warteschlange gestellt wurde. Das KI-basierte Spam-Präventionssystem SpamBrain hatte den Link-Graphen und die Inhaltsdatenbanken im Vorfeld analysiert und Ziel-Domains sowie Verletzungsmuster markiert. Die offizielle Veröffentlichung am 24. März war an sich nur die Aktivierung des Ausführungsmechanismus (Enforcement Trigger), der die vorbereiteten Strafmaßnahmen schlagartig auf den Index anwandte.
Im Gegensatz zum bedeutenden März-Update 2024, das mit der Veröffentlichung erweiterter Richtlinien einherging, wurde das März-Update 2026 als „normales Spam-Update“ (normal spam update) eingestuft. „Normal“ bedeutet im Kontext von 2026 jedoch den Einsatz von Machine-Learning-Modellen der nächsten Generation, um Verstöße gegen bestehende Regeln zu identifizieren:
- Missbrauch durch skalierte Inhalte (Scaled Content Abuse): Die SpamBrain-Algorithmen sind von der Suche nach syntaktischen Fehlern zur semantischen Analyse übergegangen. Seiten, die in industriellem Maßstab generiert werden (insbesondere unter Verwendung von Large Language Models), werden streng gefiltert, wenn sie keinen originellen Mehrwert bieten. Bestraft wird nicht die Nutzung von KI an sich, sondern der Mangel an redaktioneller Kontrolle und Informationsdichte.
- Missbrauch der Website-Reputation (Site Reputation Abuse / Parasite SEO): Das Update versetzte der Praxis der Vermietung von Unterverzeichnissen einen kritischen Schlag. Die Strategie, minderwertige Inhalte Dritter (Gutscheincodes, Glücksspiel-Links) auf den Seiten autoritärer Hosts (Nachrichtenportale, Bildungseinrichtungen) zu veröffentlichen, um deren Trust-Signale auszunutzen, wird nun algorithmisch erkannt, was zur Isolierung und Abwertung spezifischer Bereiche führt, ohne auf manuelle Strafen warten zu müssen. Vor diesem Hintergrund entfaltet sich ein regulatorischer Konflikt: Die Europäische Kommission hat bereits im November 2025 eine Untersuchung gegen Google eingeleitet, um zu prüfen, ob diese Richtlinie die legitimen Einnahmen von Nachrichtenverlagen aus gesponserten Inhalten beeinträchtigt.
- Missbrauch abgelaufener Domains (Expired Domain Abuse): Der Erwerb alter Domains mit hoher Autorität (Domain Rating) zur sofortigen Veröffentlichung irrelevanter Inhalte (z.B. die Umwandlung eines Medizin-Blogs in eine Casino-Affiliate-Site) wird vom System nun sofort identifiziert. Der Algorithmus setzt das angesammelte historische Gewicht der Domain zurück und verwandelt ein teures SEO-Investment in eine Belastung.
Bezeichnenderweise bestätigte Google offiziell, dass es innerhalb dieser 19,5 Stunden kein Targeting auf Link-Spam (link spam) gab. Die Infrastruktur des Updates konzentrierte sich ausschließlich auf die Bereinigung des Index von Inhaltsmüll und Autoritätsmanipulationen. Diese rasante Säuberung diente einem utilitaristischen Zweck – der Vorbereitung eines „sauberen“ Index für die anschließende komplexe Neuberechnung von Qualitätssignalen im Rahmen des bevorstehenden Core Updates.
Analyse der SERP-Volatilität: Registrierung des „Googlequake“
Unmittelbar nach dem Start des March 2026 Core Updates trat das Such-Ökosystem in eine Phase extremer Turbulenzen ein. Die Situation wurde dadurch verschärft, dass sich die Suchergebnisseiten (SERP) bereits seit Anfang Januar 2026 in einem Zustand permanenter Volatilität befanden, mit verzeichneten Ausschlägen am 6., 12., 15., 21. und am 26. Januar sowie am 2., 10. und 15. Februar. Die Ära diskreter, klar abgegrenzter Phasen der Instabilität wurde durch ein Regime kontinuierlicher Neukalibrierung abgelöst.
Analyseplattformen, die Positionsänderungen verfolgen, verzeichneten historische Höchstwerte bei Verschiebungen:
- Semrush Sensor: Die Plattform, die tägliche Schwankungen für Millionen von Keywords in über 20 Kategorien misst, verzeichnete einen Volatilitätswert von 9,3–9,5 von 10 möglichen Punkten. Dieses Niveau wird vom System offiziell als „Googlequake“ (Google-Erdbeben) klassifiziert, was auf eine vollständige Umstrukturierung der ersten Seiten der Suchergebnisse in den meisten kommerziellen und informativen Nischen hindeutet.
- MozCast: Das Tool, das meteorologische Metaphern verwendet, verzeichnete „stürmische“ Temperaturen, die deutlich über dem durchschnittlichen Basiswert (70°F) lagen, was auf massive Verschiebungen innerhalb der Top-10-Ergebnisse hinweist.
- Advanced Web Ranking und Accuranker (Grump): Beide Tools bestätigten tiefe Fluktuationsmuster, was auf eine parallele Neubewertung mehrerer grundlegender Ranking-Signale hindeutet.
Das Paradoxon des „Blinden Flecks“: SERP-Verschiebung (Displacement) versus echte Abwertung
Die Interpretation von Volatilitätsmetriken im Jahr 2026 erfordert ein Verständnis der fundamentalen Veränderung in der Architektur der Suchergebnisseite. Traditionelle Tools (Rank-Delta-Analysen) weisen einen kritischen blinden Fleck auf: Sie berechnen mathematisch die Position einer URL, ignorieren aber die visuelle Topologie der Seite.
Eine tiefergehende Analyse zeigt, dass ein erheblicher Teil des Verlusts an organischem Traffic nicht auf eine Verschlechterung der Inhaltsqualität oder algorithmische Strafen zurückzuführen ist, sondern auf die sogenannte „SERP-Verschiebung“ (SERP displacement). Innovationen der Benutzeroberfläche von Google haben die Aufmerksamkeitsverteilung (Click-Through Rate, CTR) radikal verändert. Die Einführung von Diskussionsmodulen (discussion modules), Produktkarussellen, erweiterten lokalen Paketen (Local Packs) und vor allem Panels der künstlichen Intelligenz (AI Overviews / SGE) verdrängt die traditionellen blauen Links physisch aus dem ersten sichtbaren Bildschirmbereich.
Eine Webseite mag ihre formelle dritte Position im klassischen Ranking behalten, wird aber für den Nutzer praktisch unsichtbar, da sie von neuen SERP-Schnittstellen überdeckt wird. Daten des Semrush Sensor-Tools bestätigen diese strukturelle Umstrukturierung: Die Häufigkeit von Blöcken mit „Ähnlichen Suchanfragen“ erreicht 96,34 %, Videoblöcke 51,76 %, AI Overview-Panels 30,64 %, während der Anteil der Suchergebnisse ohne spezielle SERP-Elemente (No SERP Features) bei marginalen 1,21 % liegt. Die aktuelle algorithmische Volatilität spiegelt nicht nur den Kampf um Positionen wider, sondern auch das Testen von Google, welche Schnittstellenformate die Suchintention am besten befriedigen.
Ranking-Architektur im März 2026: Die drei Säulen der neuen SEO
Das March 2026 Core Update markiert das Ende der transaktionalen SEO, die sich ausschließlich auf Keywords und Backlinks konzentriert. An ihre Stelle tritt eine umfassende Bewertung des Dokumentenwerts, die auf drei fundamentalen Säulen basiert: Information Gain, strenge E-E-A-T-Protokolle und technische Perfektion (Core Web Vitals).
1. Die Mechanik des Information Gain und der Tod kompilativer Inhalte
Einer der Haupttreiber der aktuellen Änderungen ist das algorithmische Gewicht der Metrik „Informationsgewinn“ (Information Gain Score), ein Konzept, das ursprünglich in Google-Patenten im Jahr 2022 beschrieben wurde und 2026 seine algorithmische Reife erreichte.
Historisch gesehen bestand die SEO-Standardpraxis (besonders verstärkt durch die Verfügbarkeit von LLMs wie ChatGPT) darin, die zehn besten Suchergebnisse zu analysieren, gemeinsame Thesen zu extrahieren und einen neuen, längeren Text zu generieren, der dieselben Fakten enthält (Consensus Content). Die Google-Algorithmen von 2026 stufen solche Inhalte als redundant ein. Per Definition erzeugt kompilativer KI-Content einen Information Gain von null, da er lediglich den Durchschnittswert des bereits indizierten Datenkorpus reproduziert.
Um unter modernen Bedingungen zu ranken, muss ein Dokument den Wert der „Perplexität“ (Perplexity) senken – ein mathematisches Maß dafür, wie überrascht ein neuronales Netzwerkmodell von neuen Daten ist. Seiten werden nach ihrer Faktendichte (Fact Density) und ihrer Fähigkeit bewertet, einen einzigartigen Beitrag zum Knowledge Graph der Suchmaschine zu leisten. Der Algorithmus belohnt ausdrücklich Inhalte, die Folgendes bieten:
- Proprietäre Datensätze und Statistiken (Ergebnisse eigener Forschung, Umfragen).
- Tiefgehende Fallstudien (Case Studies) mit realen Variablen.
- Echte persönliche Erfahrungen, die durch Roh-Mediendateien (Smartphone-Fotos, unbearbeitete Screenshots von internen Dashboards) und nicht durch Stockfotos verifiziert werden.
Content-Farmen, die Hunderte von Artikeln pro Tag mit automatisierten Prompts veröffentlichten, verloren 35 % bis 60 % ihrer Sichtbarkeit, da ihre Seiten keine Originaldaten enthielten, die Google für das Training oder die Erstellung von AI Overviews-Panels verwenden konnte.
2. Das E-E-A-T-Ultimatum und das Problem der Deanonymisierung
Das E-E-A-T-Konzept (Experience, Expertise, Authoritativeness, Trustworthiness) hat sich von Empfehlungen für manuelle Rater (Quality Raters) zu einem strengen algorithmischen Dauerfilter entwickelt. Das März-Core-Update hat die Überprüfung der Autorschaft von einem optionalen Vertrauensfaktor zu einer kritischen Voraussetzung für das Ranking gemacht, insbesondere in YMYL-Themen (Your Money or Your Life – Finanzen, Gesundheit, Sicherheit).
Die Analytik zeigt eine grundlegende Verschiebung:
- Trust Engineering: 73 % der Seiten, die nach dem März-Update Spitzenpositionen einnehmen, enthalten detaillierte Autorenprofile mit verifizierten Referenzen.
- Abwertung der Anonymität: Die Veröffentlichung von Artikeln unter unpersönlichen Tags („Von der Redaktion verfasst“, „Admin“, „Team“) wird als konkreter Faktor für eine algorithmische Herabstufung klassifiziert.
- Trust Score: Algorithmen bewerten die Expertise des Autors nicht nur innerhalb der aktuellen Website, sondern auch durch die Analyse seines externen digitalen Fußabdrucks. Wenn der Autor keine beruflichen Profile (LinkedIn), Publikationen auf Fachportalen oder Erwähnungen in der Branche aufweist, wird sein „Trust Score“ mit null gleichgesetzt. Inhalte, die von einem solchen Autor geschrieben wurden, ranken nicht für umkämpfte Suchanfragen.
- Institutionelle Transparenz: Das Vorhandensein einer detaillierten „Über uns“-Seite, einer klar formulierten redaktionellen Richtlinie und physischer Kontaktdaten wird vom Algorithmus nun als Grundvoraussetzung und nicht mehr als zusätzlicher Vorteil angesehen.
Gleichzeitig hat Google seine Haltung zur „thematischen Ausuferung“ (Topical Sprawl) verschärft. Untersuchungen basierend auf dem Leak der Google API-Dokumentation (2024) bestätigten die Existenz eines Multi-Signal-Systems zur Bewertung der thematischen Autorität (Topical Authority), das Metriken wie siteFocusScore, siteRadius und Vektor-Embeddings (topic embeddings) umfasst. Domains, die versuchen, durch die Abdeckung nicht verwandter Nischen Traffic anzuhäufen (z.B. ein SaaS-Unternehmen, das Software verkauft, aber Artikel über Remote-Work-Kultur und persönliche Produktivität veröffentlicht), werden abgewertet. Der Algorithmus belohnt Ressourcen mit einer hohen Dichte des thematischen Clusters, bei denen interne Verlinkungen (internal linking) ein klares Verständnis für die Expertennische der Marke schaffen.
3. Der technische Imperativ: Evolution der Core Web Vitals
Während die Semantik des Inhalts die Relevanz bestimmt, ist die technische Architektur der Website zu einem harten Filter für den Zugang zu Top-Positionen geworden. Das März-Update 2026 formalisierte neue, strengere Schwellenwerte für die Core Web Vitals (CWV).
Ein wesentlicher technologischer Wandel war die Evolution der INP-Metrik (Interaction to Next Paint), die die Reaktionsfähigkeit der Benutzeroberfläche auf Nutzeraktionen (Klicks, Tippen, Tastendrücke) während der gesamten Sitzung misst.
| Core Web Vitals Metrik | Was gemessen wird | Alter Schwellenwert „Gut“ | Neuer Schwellenwert „Gut“ (März 2026) | Status „Optimierung erforderlich“ |
| INP (Interaction to Next Paint) | Reaktionsfähigkeit auf Nutzeraktionen | < 200 ms | < 150 ms | 150 ms – 500 ms |
| LCP (Largest Contentful Paint) | Ladegeschwindigkeit des Hauptinhalts | < 2.5 sek | < 2.0 sek | 2.0 sek – 4.0 sek |
| CLS (Cumulative Layout Shift) | Visuelle Stabilität des Layouts | < 0.1 | < 0.1 (ohne Änderung) | 0.1 – 0.25 |
Der INP-Schwellenwert von 150 Millisekunden ist kein Zufall. Er basiert auf Wahrnehmungsstudien: Visuelles Feedback innerhalb von 100–150 ms wird vom menschlichen Gehirn als augenblicklich wahrgenommen, während Verzögerungen von über 200 ms als Trägheit des Systems und über 500 ms als Fehlfunktion empfunden werden.
Diese Verschärfung hatte verheerende Auswirkungen auf Web-Ressourcen, die auf schweren JavaScript-Frameworks (React, Next.js, Angular, Vue) aufbauen und lang andauernde Aufgaben (long tasks) im Haupt-Thread des Browsers generieren. Empirische Daten aus der Analyse von 10.000 Domains zeigen, dass Seiten, deren INP-Werte den neuen Schwellenwert überschreiten (und in die Zone > 150 ms fallen), einen algorithmischen Positionsrückgang von durchschnittlich 0,8 Punkten verzeichneten – ausschließlich aufgrund technischer Mängel. Von Ingenieuren wird nun eine tiefgehende Optimierung des clientseitigen Renderings verlangt (Nutzung von Scheduling-APIs wie useDeferredValue und useTransition in React, v-memo in Vue), um die Positionen zu halten.
Singularität im E-Commerce: Universal Commerce Protocol (UCP)
Das März-Update 2026 fiel mit einem epochalen strukturellen Wandel in der Architektur des digitalen Handels zusammen, initiiert durch den Start des Universal Commerce Protocol (UCP) von Google. Während algorithmische Änderungen die Positionen blauer Links neu mischten, veränderte UCP grundlegend die Mechanik, wie Nutzer online einkaufen.
UCP wurde in einem Konsortium mit Branchenriesen (Shopify, Walmart, Target, Etsy, Wayfair) entwickelt und mit wichtigen Zahlungs-Gateways (Stripe, Adyen, Visa, Mastercard) integriert. Es ist ein offenes, standardisiertes Kommunikationsprotokoll. Es ermöglicht KI-Agenten (wie Google Gemini, dem AI Mode in der Suche und integrierten Agenten in mobilen Betriebssystemen) den direkten Zugriff auf die Bestands- und Zahlungssysteme von Händlern, unter Umgehung der visuellen Benutzeroberflächen von Websites.
Das Ende der Ära des Conversion Funnels („Der Tod des Klicks“)
Zwei Jahrzehnte lang basierte der elektronische Handel auf der Lenkung menschlicher Aufmerksamkeit: Der Nutzer gab eine Suchanfrage ein, besuchte den Shop, studierte die Produktseite, legte den Artikel in den Warenkorb und durchlief einen mehrstufigen Checkout-Prozess. Marketer optimierten Seiten, um den ersten Klick zu ergattern und die Absprungrate (bounce rate) zu senken.
UCP lässt den gesamten Sales Funnel in einem einzigen dialogorientierten Mikromoment innerhalb der Agenten-Schnittstelle kollabieren. Die Architektur des Protokolls dekonstruiert das Einkaufen in drei maschinenlesbare Fähigkeiten (Capabilities):
- Discovery (Suche): Die KI analysiert strukturierte Kataloge, um anhand komplexer Nutzerkriterien das ideale Produkt zu finden.
- Cart (Warenkorb): Zusammenstellung der Bestellung und Anwendung von Treueprogrammen auf Seiten des Agenten.
- Checkout (Bezahlung): Nahtloser Abschluss der Transaktion unter Verwendung tokenisierter Google Pay-Daten, ohne den Nutzer auf die Domain des Händlers weiterleiten (redirect) zu müssen.
Diese Technologie überführt die Branche von einer „schnittstellenbasierten Wirtschaft“ (interface-based economy) in eine „protokollbasierte Wirtschaft“ (protocol-based economy). Für Shops, die UCP integriert haben, verliert die klassische Kennzahl „Website-Traffic“ an Aussagekraft; der entscheidende KPI wird das Volumen der von künstlicher Intelligenz initiierten Verkäufe.
Der Übergang von SEO zu AEO und Feed-Engineering
Die Integration von UCP erfordert eine radikale Umstrukturierung der digitalen Marketingstrategien. Da KI-Agenten selbstständig entscheiden, welche Produkte sie dem Nutzer für einen schnellen Kauf empfehlen und anzeigen, verlagert sich der Fokus von der textbasierten SEO auf AEO (Agent Engine Optimization / Answer Engine Optimization) und GEO (Generative Engine Optimization).
Das Hauptschlachtfeld im Jahr 2026 ist die Datenhygiene und das Produkt-Feed-Engineering. KI-Agenten sind im Gegensatz zu Menschen nicht anfällig für überzeugendes Copywriting oder grelle Banner; sie arbeiten mit strengen JSON-Strukturen. Damit ein Produkt für eine UCP-Transaktion ausgewählt wird, muss es strenge maschinenlesbare Kriterien erfüllen:
- Attribut-Konsistenz: Jegliche Abweichung zwischen Preis oder Verfügbarkeitsstatus im Google Merchant Center Feed und den realen Daten im Backend des Händlers führt zum sofortigen Ausschluss des Produkts aus den Empfehlungen des KI-Agenten.
- Granulares Schema-Markup: Agenten benötigen tiefgehende strukturierte Daten über Materialeigenschaften, Abmessungen, Anwendungsfälle und Rückgaberichtlinien (return policy). Der Erfolg hängt davon ab, wie detailliert das Produkt auf Code-Ebene beschrieben ist, damit die KI es mit komplexen, mehrteiligen Nutzeranfragen abgleichen kann (z.B. „Wasserdichte Laufschuhe für Überpronation mit Lieferung bis morgen“).
- Echtzeit-Synchronisation: Händler müssen von veralteten Methoden des Batch-Uploads von Feeds (Content API) auf Streaming-Methoden (Merchant API) umsteigen, um eine sofortige Aktualisierung der Bestände zu gewährleisten.
Für Einzelhändler stellt die UCP-Einführung ein komplexes Dilemma dar. Einerseits eröffnet die Anbindung an das Protokoll den Zugang zu Millionen von Transaktionen über smarte Geräte und die Suchmaschine ohne Reibungsverluste für den Käufer. Andererseits verliert der Verkäufer die Kontrolle über die visuelle Präsentation der Marke und einen Teil der Möglichkeiten für Up-Selling, da der Nutzer das Schaufenster des Shops nicht mehr betrachtet. Das Ignorieren von UCP birgt jedoch ein existenzielles Risiko: KI-Agenten bevorzugen algorithmisch jene Produkte, die ein nahtloses (frictionless) Kauferlebnis bieten. Marken, die vom Nutzer verlangen, auf einen Link zu klicken, auf das Laden der Website zu warten, sich zu registrieren und eine Kartennummer einzugeben, werden in den kommerziellen Suchergebnissen der Zukunft abgewertet.
Die Auswirkungen von AI Overviews auf den Informations-Traffic
Der Einfluss künstlicher Intelligenz auf das Suchverhalten beschränkt sich nicht auf den E-Commerce. Studien von Ahrefs, die im Dezember 2025 durchgeführt wurden (vor dem März-Core-Update, aber nach dem massenhaften Rollout der generativen Suche), zeigen die verheerenden Auswirkungen der AI Overviews-Panels auf die Klickrate bei informativen Suchanfragen.
Einer Analyse von 300.000 Keywords zufolge verringert das Vorhandensein eines AI Overview-Blocks die durchschnittliche Klickrate (CTR) für die erstplatzierte Seite in den organischen Ergebnissen um 58 %. Historische Daten zeigen, dass im Dezember 2023 (vor der Einführung von SGE) die durchschnittliche CTR für die erste Position bei Informationsanfragen bei 0,076 lag. Bis Dezember 2025 stürzte dieser Wert auf 0,039 ab. Informationsanfragen („Zero Clicks“) werden nun vollständig von KI-Synthesemechanismen direkt auf der Suchseite verarbeitet, was Medienseiten und Blogs den Löwenanteil des organischen Traffics entzieht. Die verbleibenden Klicks (auf Marken- oder Transaktionsanfragen) weisen eine höhere Kaufabsicht (Intent) auf, ihre absolute Anzahl nimmt jedoch stetig ab.
Sektorale Analyse: Gewinner und Verlierer
Da das Google March 2026 Core Update auf einem vergleichenden Ranking basiert (bei dem Positionen zwischen Domains umverteilt und nicht isoliert vergeben werden), ist der organische Traffic ein Nullsummenspiel. Die Analyse der Sichtbarkeitsdatenbanken (Sistrix, Ahrefs, Semrush) in den ersten Tagen nach dem Rollout offenbart klar ausgeprägte sektorale Muster.
Domains mit Wachstum (Die Gewinner)
- User-Generated Content (UGC) Plattformen und Communities: Der Google-Algorithmus fördert weiterhin aggressiv Ressourcen, die unaufbereitete, ungefilterte menschliche Erfahrungen sammeln. Die Plattformen Reddit, Yelp, Quora sowie spezialisierte Branchenforen verzeichneten ein deutliches Wachstum der Sichtbarkeit. Diese Seiten bieten authentische Problemlösungen, die algorithmisch sterilen und durchkalkulierten Artikeln von Content-Farmen entgegengestellt werden.
- Strukturierter Marken-E-Commerce: Einzelhändler, die eine perfekte Übereinstimmung mit dem transaktionalen Intent und technische Perfektion (Geschwindigkeit, INP, strukturierte Daten) bieten, wurden zu den Hauptprofiteuren. In regionalen Studien wurde ein massiver Anstieg der Sichtbarkeit bei Uniqlo.com (+76 %) und Notonthehighstreet.com (+56 %) verzeichnet. In den USA wurden ähnliche Trends bei HomeDepot.com festgestellt.
- Hochspezialisierte Expertenressourcen (Niche Authority): Blogs und Publikationen, die sich auf ein einziges Thema konzentrieren (Topical Authority) und regelmäßig unabhängige Forschungsberichte, Primärdaten oder Produkttests veröffentlichen, zeigten einen durchschnittlichen Sichtbarkeitszuwachs von 22 %.
- Auf persönliche Erfahrung ausgerichtete Websites (First-person experience): Artikel, die die reale Nutzung eines Produkts mit einzigartigem Fotomaterial demonstrieren, setzten ihren Aufwärtstrend fort und bestätigten die Bedeutung des Buchstabens „E“ (Experience) im Akronym E-E-A-T.
Algorithmisch abgewertete Domains (Die Verlierer)
- Websites mit „Programmatic SEO“: Domains, die die Taktik der automatisierten Generierung von Zehntausenden gleichartiger Landingpages (z. B. Geo-Targeting der Art „Dienstleistung + Stadt“ oder Kombinationen von Attributen wie „Kategorie + Farbe + Marke“) anwandten, erlitten katastrophale Verluste. Der Algorithmus fordert nun für jede einzelne URL einen erheblichen Mehrwert. Die Domain Bluettipower.com wurde in der Analytik als anschauliches Beispiel für die Abwertung aufgrund von programmatischem Content hervorgehoben.
- Die SaaS-Branche und KI-Aggregatoren: Software-as-a-Service-Unternehmen, die die oberen Ebenen ihrer Marketing-Funnel (ToFu) durch die massenhafte Veröffentlichung von KI-Artikeln (ohne Beteiligung von Fachredakteuren und Angabe fachkundiger Autoren) aufgebaut haben, erlebten einen Sichtbarkeitseinbruch von 35–60 %.
- Diskrepanz zwischen Autorität und Suchintention (Intent Mismatch): Das März-Update hat bewiesen, dass der historische Trust einer Domain nicht ausreicht, um Positionen zu halten, wenn die UX nicht den Bedürfnissen des Nutzers entspricht. Das deutlichste Beispiel war der Absturz des britischen Regierungsportals hmrc.gov.uk (Steuerbehörde), dessen Sichtbarkeit zeitweise um 50 % sank. Nutzer, die klare Anweisungen suchten, stießen auf eine verwirrende Navigation, was zu Rückkehrern in die Suchergebnisse (Pogo-Sticking) und einer Herabstufung der Seiten im Ranking führte. Große Bekleidungsmarken und Marktplätze wie Zara (-24 %) und Amazon (-14 %) verloren ebenfalls einen Teil ihrer Sichtbarkeit aufgrund der Neukalibrierung der Algorithmen zur Intent-Bestimmung.
- Affiliate-Sites mit „dünnen“ Inhalten (Thin Affiliates): Webmaster, deren Geschäftsmodell auf dem Scraping von Produktspezifikationen von Herstellerseiten aufbaute (ohne Einbindung eigener Bewertungen, Videotests und vergleichender Analysen), wurden von den ersten Seiten der Suchergebnisse gefegt.
- Degradierte Foren: Bemerkenswert ist, dass trotz des allgemeinen Trends zugunsten von UGC Foren mit geringer Diskussionsqualität (viel Spam, Fehlen ausführlicher Antworten, Duplizierung von Threads), wie DIYChatroom und GarageJournal, ihre Positionen verloren, die sie während der Updates im Jahr 2025 gewonnen hatten.
Reaktion der Fachwelt: Die Anpassungskrise
Der Rollout des März-Updates löste eine beispiellose Resonanz unter digitalen Marketern, SEO-Ingenieuren und Webmastern aus. Die Diskussionen auf den Fachplattformen (WebmasterWorld, Reddit, spezialisierte Slack-Communities) offenbarten die Tiefe der strukturellen Krise in der Branche.
Das Phänomen der „Combo-Updates“ und die Erschöpfung der Branche: Die Veröffentlichung des Core-Updates nur wenige Tage nach dem Spam-Update löste eine Welle der Frustration aus. Die Branchenexpertin Aleyda Solis beschrieb die Situation auf der Plattform X (Twitter) ironisch als „Combo-Updates“. In den WebmasterWorld-Foren überwog die Stimmung algorithmischer Erschöpfung: Webmaster sprachen von einem „permanenten täglichen Absturz-Modus“ (constant daily drop mode) und totalem Chaos in den SERPs, bei dem jahrelang gehaltene Positionen verschwanden, durch irrelevante Ergebnisse in Fremdsprachen ersetzt wurden und dann plötzlich für einige Tage zurückkehrten.
Diskussionen in r/SaaS und r/SEO: Das Ende der Generierungs-Ära Die dramatischsten Diskussionen entfalteten sich in Reddit-Communities. Im Subreddit r/SaaS teilten Nutzer Berichte darüber, wie die Strategie, „50 Artikel mit KI zu generieren und auf Backlinks zu beten“, über Nacht vollständig vernichtet wurde. Startup-Gründer verzeichneten Traffic-Einbrüche und betonten, dass es den Google-Algorithmen inzwischen „egal ist, wie gut man den Prompt für die KI formuliert hat“ – wenn hinter dem Text keine echte Expertise und kein klares Autorenprofil stehen, wird er abgewertet.
In der Community r/SEO (Thread „The Great Reset“ / „Der Tod der Manipulationen“) konstatierten Marketer das Ende der Ära der leichten SEO. Nutzer stellten fest, dass Google begonnen hat, „digitale Fußabdrücke“ von PBN-Netzwerken (Private Blog Networks) aufzuspüren, indem es identische WordPress-Vorlagen und gemeinsames Hosting identifiziert, was dazu führt, dass gekaufte Links nun aktiven Schaden für das Domain-Rating anrichten. Die Nutzlosigkeit von „Parasite SEO“ auf vertrauenswürdigen Domains (wie im Fall des Absturzes der Forbes-Unterverzeichnisse) und die völlige Diskreditierung des Kaufs abgelaufener (expired) Domains wurden ebenfalls hervorgehoben.
Interne organisatorische Risiken von SEO-Teams: Die Branchenanalysten von Search Engine Land wiesen auf einen paradoxen Trend hin: Im Jahr 2026 geht die Hauptgefahr für SEO nicht von den Google-Algorithmen selbst aus, sondern von der internen Desorganisation unternehmerischer Teams. Eine massenhafte, unkontrollierte Automatisierung von Prozessen (Generierung von Briefings, Texten, Daten-Scraping ausschließlich durch KI) hat zur Produktion von durchschnittlichen Inhalten geführt. Unternehmen, die dieselben LLM-Tools zur Lösung derselben Aufgaben einsetzen, erhalten identische Ergebnisse ohne einen „einzigartigen Blickwinkel“ (Point of View), was in der Ära des Information Gain fatal ist. Die Fragmentierung der Daten zwischen den Entwicklungs- und Marketingabteilungen führt dazu, dass kritische technische Anpassungen (INP-Optimierung, Schema-Hygiene für UCP) mit erheblicher Verzögerung implementiert werden.
Strategisches Anpassungs- und Wiederherstellungsprotokoll (Recovery Guide)
Angesichts der algorithmischen Singularität, die durch das March 2026 Core Update geformt wurde, sind Versuche, das System mit punktuellen technischen Tricks zu „überlisten“, sinnlos. Die Wiederherstellung verlorener Positionen erfordert eine tiefgreifende organisatorische Umstrukturierung und die vollständige Akzeptanz des E-E-A-T-Paradigmas sowie der Product-Led SEO.
Basierend auf offiziellen Empfehlungen der Suchmaschine, Analysen von Experten (wie Glenn Gabe, Lily Ray, Marie Haynes) und technischen Protokollen sollte der Handlungsalgorithmus für Unternehmen in folgenden Phasen strukturiert werden.
Phase 1: Moratorium für Eingriffe (Isolationsperiode)
Die erste und kritischste Regel des professionellen SEO-Engineerings lautet: Ein kategorisches Verbot radikaler Änderungen (Panic Edits) an der Architektur oder den Inhalten der Website bis zum offiziellen Abschluss des Update-Rollouts. Gemäß dem Status auf dem Google Search Status Dashboard dauert der Prozess bis zu 14 Tage (voraussichtlich bis zum 10.–11. April 2026). In dieser Phase führen die Algorithmen mehrstufige Berechnungen und die Kalibrierung von maschinellen Lernsystemen durch. Die Traffic-Fluktuationen sind chaotisch: Eine Seite, die am zweiten Tag abgestürzt ist, kann ihre Positionen bis zum Ende des Zyklus eigenständig wiedererlangen. Code-Modifikationen oder das Löschen von Inhalten während der aktiven Sturm-Phase würden die Reinheit der Diagnosedaten unwiderruflich zerstören.
Phase 2: Klinische Diagnose der Verluste
Mindestens 7 Tage nach dem bestätigten Ende des Updates muss der Prozess zur Zuordnung der Änderungen gestartet werden :
- Isolierung von Mustern in GSC und GA4: Führen Sie einen strikten Kohortenvergleich durch: 14 Tage vor dem Update (vor dem 27. März) im Vergleich zu 14 Tagen nach dem vollständigen Abschluss. Die Aufgabe besteht darin, herauszufinden, ob die Verluste globaler Natur sind (site-wide) oder auf bestimmte Cluster beschränkt sind (z. B. nur der von neuronalen Netzen generierte Blog oder Serviceseiten ohne Autorenangabe).
- Segmentierung der Oberflächen: Trennen Sie Traffic-Verluste in der primären Websuche von Rückgängen im Google Discover-Feed und in den Reitern News und Images. Da die algorithmischen Pipelines für diese Oberflächen nun differenziert sind (was das Februar Discover Update bewiesen hat), unterscheiden sich auch die Wiederherstellungsstrategien für sie.
Phase 3: Audit auf Basis von Information Gain und E-E-A-T
Die algorithmische Abstrafung im Jahr 2026 ist keine Strafe für einen Fehler, sondern die Feststellung der Tatsache, dass die Ressource in einem wettbewerbsintensiven Umfeld weniger nützlich geworden ist.
- Sanierung von kompilativem Müll (Content Pruning): Sämtliches Material, das ausschließlich durch das Umschreiben der SERPs oder mithilfe einfacher ChatGPT-Prompts erstellt wurde, muss gnadenlos gelöscht (Status 410) oder strikt konsolidiert werden.
- Injektion von Fakten (Fact Density): Der zu aktualisierende Inhalt muss mit proprietären Daten angereichert werden. Die Einführung eigener Statistiken, einzigartiger Grafiken, Video-Beweise von Produkttests und Case Studies ist der einzige Weg, den Information Gain zu steigern.
- Deanonymisierung und Trust Engineering: Für Seiten der YMYL-Kategorie ist das Fehlen verifizierter Autoren fatal. Detaillierte Autorenprofile mit überprüfbaren Auszeichnungen, Links zu externen Publikationen und beruflichen Netzwerken müssen zwingend implementiert werden. „Über uns“-Seiten (About Us), redaktionelle Richtlinien und physische Kontaktdaten müssen vorhanden sein und vom Algorithmus leicht identifiziert werden können.
Phase 4: Technische Umstrukturierung (CWV und UCP)
Technische Faktoren sind kein „Bonus“ mehr, sondern ein kritischer Grenzwert:
- Optimierung der Core Web Vitals: Entwickler sind verpflichtet, sicherzustellen, dass das Largest Contentful Paint (LCP) in weniger als 2,0 Sekunden geladen wird. Höchste Priorität hat die Anpassung an den neuen Schwellenwert für Interaction to Next Paint (INP) von < 150 Millisekunden. Für Websites auf React, Angular und Vue erfordert dies eine sofortige Überarbeitung der Rendering-Architektur (Implementierung von Patterns wie
useDeferredValue,v-memo, Micro-Bytecode und aggressivem Caching), um den Haupt-Thread des Browsers zu entlasten und eine sofortige Reaktionsfähigkeit der Benutzeroberfläche zu gewährleisten. - Bereitschaft für Agentic Commerce (UCP): E-Commerce-Unternehmen müssen sich an das Universal Commerce Protocol anpassen. Dies erfordert perfekte Hygiene bei strukturierten Daten (Schema.org) auf Produktseiten, den Verzicht auf Batch-Uploads von Feeds zugunsten der Merchant API für Echtzeit-Bestandssynchronisationen sowie die Implementierung von semantischem Markup für Filteroptionen (Materialien, Abmessungen, Kompatibilität). Ohne diese Maßnahmen bleiben Integrationen mit KI-Agenten (Google AI Mode, Gemini) und „Zero-Click“-Transaktionen unzugänglich.
Phase 5: Diversifikation und Product-Led SEO
Die Wiederherstellung des algorithmischen Vertrauens ist ein Marathon, der 2 bis 6 Monate systematischer Arbeit bis zur nächsten globalen Kernneuberechnung (Core Update) beansprucht. Die ausschließliche Abhängigkeit von organischem Google-Traffic im Zeitalter der Agentic Search wird zu einem existenziellen Geschäftsrisiko.
Die moderne Strategie erfordert den Übergang zu Product-Led SEO. Der Fokus sollte darauf liegen, ein eigenständiges, gefragtes Produkt zu entwickeln, nach dem Nutzer gezielt suchen (Branded Search). Der Aufbau einer loyalen Community durch E-Mail-Newsletter, soziale Netzwerke und geschlossene Telegram-Kanäle schafft unabhängige Traffic-Quellen und generiert Verhaltenssignale, die Google-Algorithmen als höchstes Maß an Vertrauen in die Marke interpretieren.
Zusammenfassung
Das Google March 2026 Core Update hat einen Schlussstrich unter die Ära des mechanistischen Suchmaschinenmarketings gezogen. In Kombination mit einem radikalen Spam-Update und der Einführung des UCP-Protokolls hat Google die Transformation seines Ökosystems von einem Transitkatalog für Links hin zu einer allumfassenden generativen Engine für die Synthese von Antworten und direkten kommerziellen Transaktionen vollendet.
Die Algorithmen von 2026 verfügen über die Rechenleistung für die mathematische Bewertung der Inhaltseinzigartigkeit (Information Gain), die Verifikation echter menschlicher Erfahrungen (E-E-A-T) und die Messung psychophysiologischer Schwellenwerte für Schnittstellenverzögerungen (INP 150ms). Um in dieser neuen Singularität relevant zu bleiben und ein nachhaltiges Geschäftswachstum zu sichern, müssen sich Unternehmen von den Taktiken der industriellen Content-Generierung und Link-Manipulation verabschieden. Sie müssen stattdessen ihre Investitionen auf tiefe datentechnische Optimierung, die Entwicklung einer authentischen Marke und die Schaffung eines nahtlosen Nutzererlebnisses konzentrieren, das sich nahtlos in das Ökosystem von KI-Agenten integrieren lässt.
Andere Artikel: